BoostKit干货店|同样硬件,Ceph存储性能提升10倍
在华为全联接2021上,鲲鹏应用使能套件BoostKit(以下简称“鲲鹏BoostKit”)正式升级为2.0,提供 “数据亲和”加速组件,对数据全处理流程进行负载优化,从而大幅提升应用性能。本期由华为计算产品线算法专家陈泽晖和何智文向大家展示鲲鹏BoostKit 2.0分布式存储全局缓存(Global Cache)特性如何做到数据存储和处理的倍数级加速能力。在摩尔定律的驱使下,计算能力倍数级增长,
在华为全联接2021上,鲲鹏应用使能套件BoostKit(以下简称“鲲鹏BoostKit”)正式升级为2.0,提供 “数据亲和”加速组件,对数据全处理流程进行负载优化,从而大幅提升应用性能。本期由华为计算产品线算法专家陈泽晖和何智文向大家展示鲲鹏BoostKit 2.0分布式存储全局缓存(Global Cache)特性如何做到数据存储和处理的倍数级加速能力。
在摩尔定律的驱使下,计算能力倍数级增长,但数据传输速度过慢导致大量计算资源浪费,也限制了系统性能发挥。例如,在金融行业,银行逐步采用AI技术对客户信息、远程开户录像、客服中心语音、企业资料等数据进行挖掘与利用,对海量文件的读写会占用大量计算资源,导致业务处理效率降低。
(原生Ceph IO请求的处理路径长,导致IO时延高,用户数据读写时间长)
鲲鹏BoostKit分布式存储全局缓存应运而生,通过缓存前后台分离、IO聚合、智能预取三大创新技术实现典型读写场景IOPS提升10倍,IO时延降低90%,意味着同样时间内银行处理的交易笔数提升10倍,而且每笔交易处理时长降低90%!
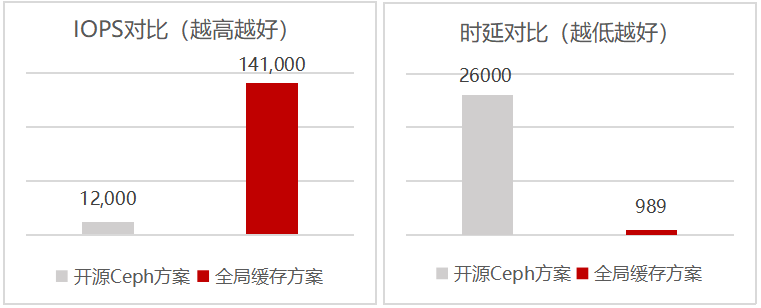
(测试模型:4K IO,7:3混合随机读写;硬件配置:256GB内存,25GE网络,每节点12 * 8TB SATA HDD,2 * 3.2TB NVMe SSD)
下面带你1分钟get三大创新技术:
1. 缓存前后台分离——缩短数据处理路径:降低IO请求的线程数量,上层应用只需要将数据写入到缓存池或从缓存池中读取即可响应用户请求。
(在数据写入场景,数据到写缓存后就可以给上层应用返回数据写入成功,无需与后台Ceph存储集群等分布式存储软件交互,用户业务应用无感知)
2. 智能预取——读加速:将数据提前加载至读缓存,实现80%以上缓存命中率和2倍以上读性能加速。
(基于IO数据统计,智能分析IO模型特征,实现缓存命中率大幅提升)
3. IO聚合——写加速:技术通过批量数据聚合,实现全周期随机写入转顺序写入,实现满带宽性能。
(在缓存中把各种大小的数据块聚合成以8M为单位的大数据块,从随机小IO转变成顺序大IO写入后端Ceph等分布式存储集群)
此外,BoostKit全局缓存面向鲲鹏生态,结合硬件特点开展软硬协同优化,如CPU亲和、NUMA亲和等,进一步达到“数据亲和”,在不增加硬件成本的前提下,全局缓存面向全命中和真实业务负载提供2~10倍端到端读写性能加速能力。

鲲鹏展翅 立根铸魂 深耕行业数字化
更多推荐
 0
0 0
0- 0



 已为社区贡献315条内容
已为社区贡献315条内容

所有评论(0)